
딥러닝이 자연어 처리(NLP)에서 크게 발전한 이유 중 하나는 Encoder-Decoder 구조와 이를 확장한 Transformer 모델 덕분입니다. 이 글에서는 Encoder-Decoder의 개념과 작동 방식, 한계점 그리고 Transformer을 설명합니다.
왜 Encoder-Decoder가 필요할까?
✔︎ 순차 데이터의 문제
자연어 문장은 입력과 출력의 길이가 다를 수 있고, 단어의 순서가 달라질 수도 있습니다. 예를 들어 영어 문장 “The baby can walk”을 한국어로 번역하면 “그 아기는 걸을 수 있다”처럼 구조가 완전히 달라집니다.
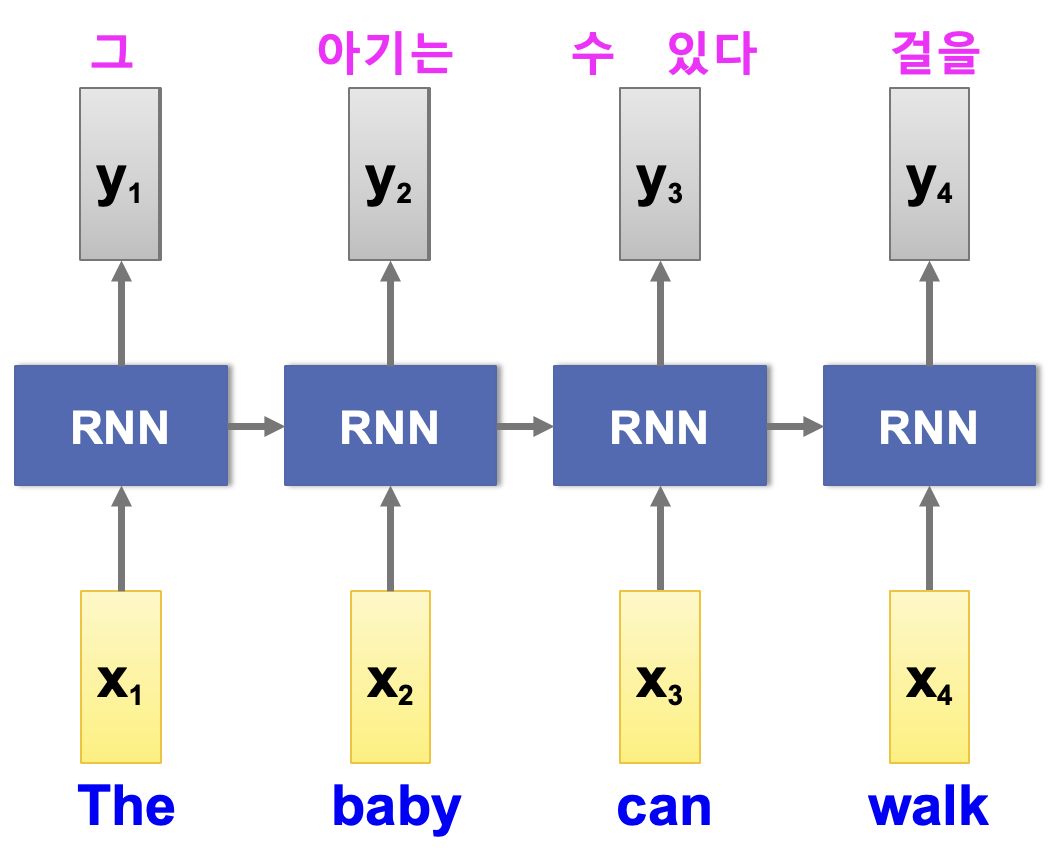
기존 RNN은 입력과 출력의 길이가 동일한 경우에는 잘 작동했지만, 이런 문제를 처리하기 어렵습니다. 이를 해결하기 위해 나온 것이 바로 Encoder-Decoder 구조입니다.
Encoder-Decoder 구조
Encoder-Decoder는 두 개의 RNN을 연결한 구조입니다.

- Encoder(인코더): 앞쪽 RNN으로, 입력 시퀀스(ex. 문장)를 압축하여 하나의 고정된 크기의 은닉 상태(hidden state) 벡터로 만듭니다. 이는 입력 문장의 모든 정보를 압축하는 역할을 합니다.
- Decoder(디코더): 뒤쪽 RNN으로, 인코더가 압축한 정보를 바탕으로 출력 시퀀스를 생성합니다.

학습은 병렬 데이터(예: 원문과 번역문 쌍)를 사용하여 Encoder와 Decoder의 파라미터(U, V, W)를 초기화하고, 예측값과 정답값 간의 Cross Entropy Loss를 최소화하는 방식으로 진행합니다.
1. 데이터 준비
- 입력 시퀀스와 목표(정답) 시퀀스를 준비합니다
2. 인코더 과정
- 입력 시퀀스를 임베딩(Embedding)하여 벡터로 변환합니다.
- 순환신경망 계열 네트워크를 거치며 시퀀스 정보를 압축합니다.
- 마지막 상태 혹은 전체 시퀀스 정보를 컨텍스트 벡터로 출력합니다.
$$ h_{t} = tanh(W_{enc} \times h_{h-1} + U_{enc} \times x_{t}) $$
3. 디코더 과정
- 디코더는 컨텍스트 벡터를 입력받아, 목표 시퀀스의 처음(시작 토큰)부터 한 단계씩 다음 단어를 예측합니다.
- 각 단계에서 이전 출력(또는 정답)을 입력으로 받아, 다음 단어의 확률 분포를 예측합니다.
$$ y_{t} = softmax(V_{dec} \times s_{t}) $$
4. Loss 계산 및 역전파
- 디코더가 예측한 시퀀스와 실제 목표 시퀀스 간의 Loss(손실)를 계산합니다.
- 주로 Cross Entropy Loss 사용
- 계산된 Loss를 바탕으로 오차 역전파(Backpropagation)를 수행하여 가중치를 업데이트합니다.
$$ Loss = -\sum_{}^{i}t_{i} \times log(y_{i}) $$
5. 반복 학습
- 위 과정을 여러 번 데이터셋 전체에 대해 반복하면서 모델이 점차 입력-출력 매핑을 학습합니다.
Encoder-Decoder의 한계: Information Bottleneck
Encoder-Decoder는 입력 문장의 모든 정보를 하나의 벡터에 압축합니다. 이 과정에서 문제가 발생합니다.
Information Bottleneck이란?
- 긴 문장일수록 압축 벡터에 모든 의미를 담기 어렵습니다.
- 중요한 정보가 손실될 가능성이 커져 번역 품질이 떨어집니다.
예시. “The baby can walk” → 압축 → 그 아기는 걸을 수 있다
⍢ 짧은 문장은 괜찮지만, 긴 문장이나 복잡한 문맥은 제대로 복원되지 못합니다.
Attention: 정보 손실을 막는 해결책
이 한계를 해결하기 위해 Attention 메커니즘이 제안되었습니다. 즉, 인코더의 모든 상태를 디코더가 참조할 수 있도록 하여 보다 정확한 예측이 가능하게끔 만들어줍니다.
출력 단어를 생성할 때 입력 문장의 특정 단어들에 집중하자!

Attention 메커니즘이란 딥러닝 모델이 입력 데이터의 모든 부분을 동일하게 취급하지 않고, 출력에서 어떤 부분(ex. 단어, 토큰, 이미지 위치 등)이 보다 중요한지 집중해서 더 높은 가중치를 부여하는 원리입니다.
쉽게 말해, 사람이 문장에서 중요한 단어에 더 신경을 쓰듯, 인공지능도 특정 정보에 더 많이 주의를 기울이며 이해하거나 생성하는 것입니다.
- 압축 벡터 하나 대신 Encoder의 모든 hidden state를 사용
- 각 출력 단어마다 입력 단어들의 중요도를 계산 (가중치 부여)
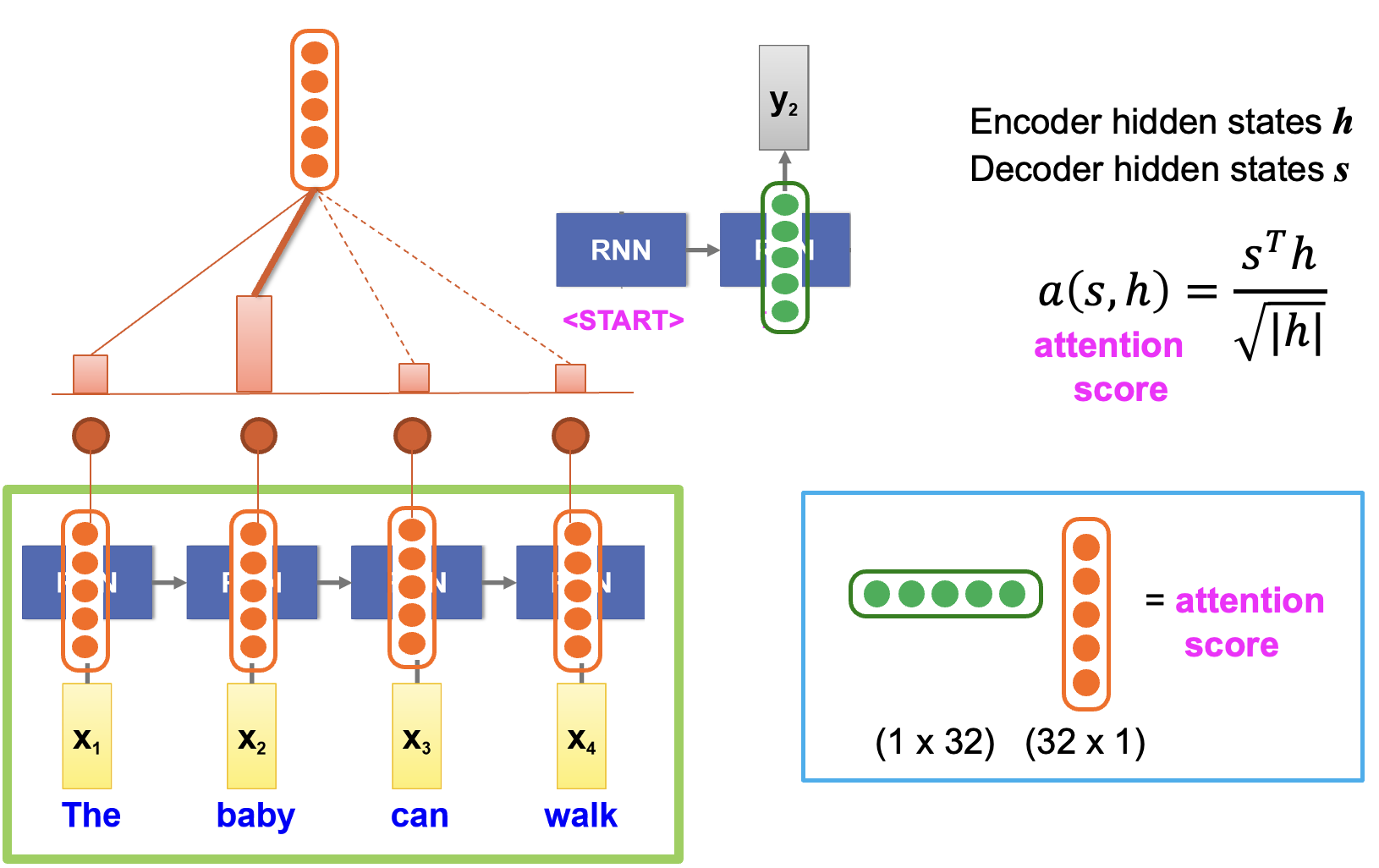
1. Decoder가 출력 단어를 생성할 때, 입력 문장 전체를 스캔
2. 각 입력 단어의 중요도를 나타내는 Attention Score 계산
- attention score: 디코더의 현재 상태(Query)와 인코더의 각 상태(Key) 사이의 유사성을 계산 → 내적
- $ s_t $ : Decoder의 현재 hidden state
- $ h_i $: Encoder의 i번째 hidden state
3. 이 점수를 Softmax로 확률화하여 가중합(weighted sum)을 계산
- softmax: 가장 중요환 부분의 값이 높아지고 전체 합이 1이 되도록 함
- weighted sum: 인코더의 각 상태(value)에 어텐션 가중치를 곱해 모두 더함
4. 중요한 입력 단어일수록 더 큰 가중치를 부여
Transformer: Attention의 확장
트랜스포머는 어텐션 메커니즘을 한 단계 더 발전시킨 인공지능 모델의 아키텍처입니다. 기존 RNN이나 CNN 없이 어텐션만을 활용해 자연어 처리(NLP), 번역, 요약 등 다양한 작업에서 탁월한 성능을 보이고 있습니다.
Transformer의 핵심
- RNN 제거: 순차적 연산 없이 병렬 처리 가능
- Self-Attention 도입: 각 단어가 문장 내 다른 단어들과 관계를 계산
- Encoder-Decoder 구조 유지, 하지만 더 빠르고 효율적
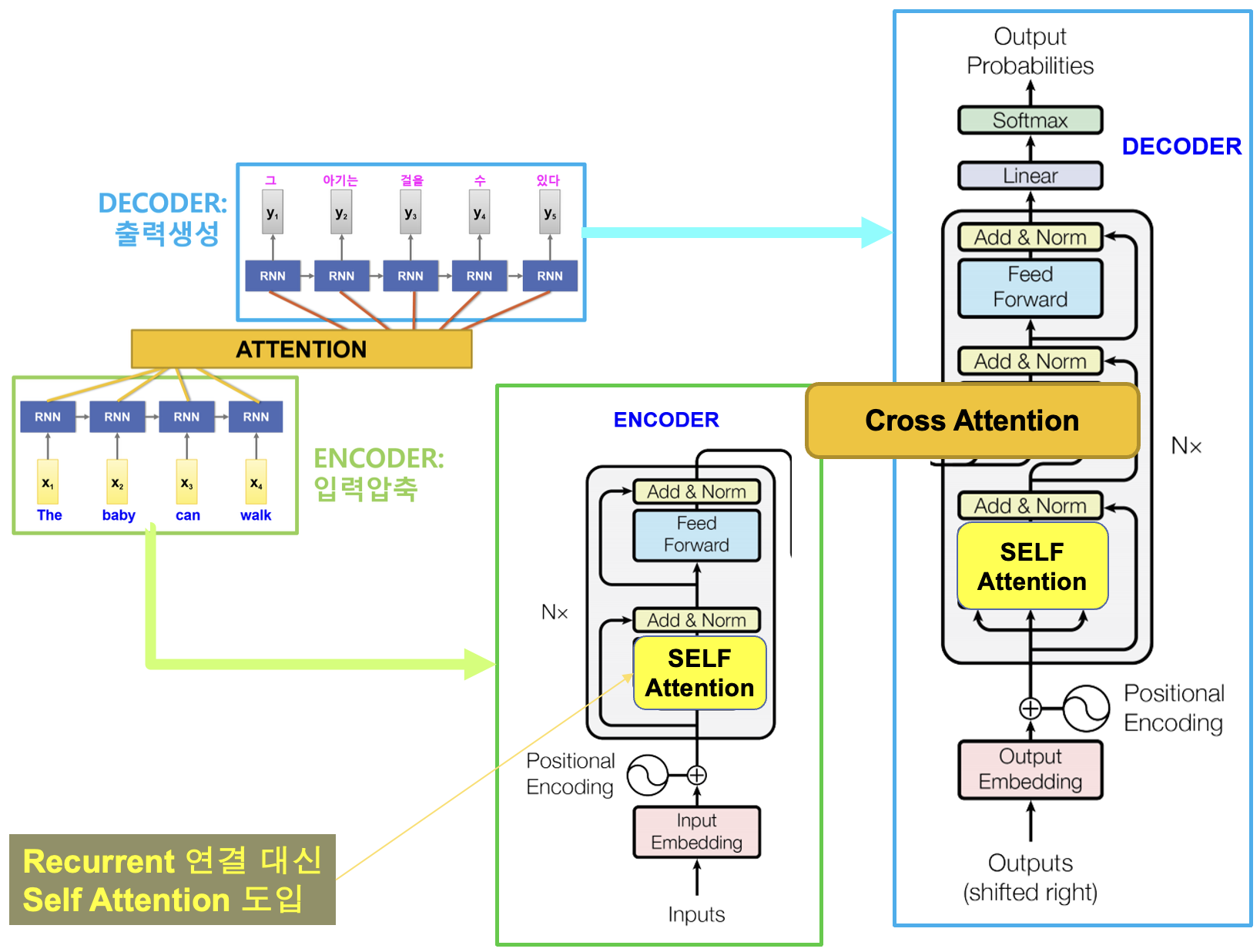
Transformer 동작 과정
1. 입력 임베딩 및 위치 인코딩
자연어의 각 단어(토큰)를 고정 크기의 벡터로 변환하여 처리합니다.
- 예를 들어 “The cat sat”이라는 문장이 입력되면 각 단어는 다음과 같이 벡터로 바뀝니다: The→[0.1,0.5,0.2,...]
- 이 임베딩 벡터는 단어의 의미를 수치화한 것으로, 비슷한 의미의 단어들은 벡터 공간상 가까이 위치합니다.
Transformer는 RNN처럼 순차적으로 데이터를 처리하지 않기 때문에, 단어의 순서 정보를 직접 알지 못합니다.
이를 해결하기 위해 각 단어 벡터에 위치 정보(position encoding)를 더해줍니다.
$$ Input=Embedding+Position Encoding $$
- "The cat sat"와 "Sat cat the"는 같은 단어들로 구성돼 있지만, 의미가 완전히 다릅니다.
- 따라서 단어의 위치 정보를 반영해야 문맥을 올바르게 이해할 수 있습니다.
2. 인코더 구조
인코더는 여러 층(Layer, 논문 기준 6층)으로 구성되며, 각 층은 Self-Attention과 Feed-Forward Neural Network로 이루어져 있습니다.
- Self-Attention: 입력 문맥 파악
- Self-Attention은 입력 시퀀스의 모든 단어 쌍 간의 관계를 계산합니다.
- 예를 들어 "The animal didn’t cross the street because it was tired"에서, “it”이 무엇을 가리키는지 이해하려면 앞의 단어들과 관계를 파악해야 합니다
- 입력 임베딩에서 Query(Q), Key(K), Value(V) 세 가지 벡터를 생성
- Query와 Key를 내적해 유사도 점수(Attention Score) 계산
- Softmax로 점수를 확률화 → 중요도를 결정
- Value 벡터들과 가중합 → 새로운 단어 표현 생성
- 결과: 각 단어는 입력 시퀀스 내 다른 단어들과의 관계를 반영한 벡터로 업데이트됩니다.
- Feed-Forward Neural Network: 비선형 반환
- Self-Attention으로 업데이트된 각 단어 벡터에 독립적으로 비선형 변환을 적용합니다.
- 입력 → 선형변환 → 활성화 함수(ReLU 등) → 또 선형변환
- 안정화 기술
- 각 인코더 층에는 잔차 연결(Residual Connection)과 정규화(Layer Normalization)가 추가되어 학습을 안정화합니다.
- 잔차 연결: 입력을 출력에 더해 정보 손실 방지
- 정규화: 값의 스케일을 일정하게 유지
3. 디코더 구조
디코더도 여러 층(6층)으로 구성되며, 각 층은 세 가지 부분으로 나뉩니다.
- Masked Self-Attention: 올바른 순서로 출력 생성
- 디코더는 이전에 생성된 단어만 참고해 다음 단어를 생성해야 합니다.
- 이를 위해 미래 단어를 가리는 마스킹(Masking)을 적용합니다.
- 예: <start> The → 다음 단어 예측 시 “The”까지만 참고
- Cross-Attention: 인코더 출력 참고
- Cross-Attention은 인코더의 출력(hidden states)을 참고해 입력 시퀀스의 어느 부분에 집중해야 할지 결정합니다.
- 예: “그 아기는” → 인코더의 “The baby”에 집중
- 피드포워드 신경망
- 인코더와 동일한 방식으로 각 단어 벡터에 독립적으로 비선형 변환을 수행합니다.
- 이 과정에서도 잔차 연결과 정규화가 함께 사용됩니다.
4. 출력 생성
디코더의 각 단계에서는 이전에 생성된 토큰들과 인코더의 정보를 바탕으로, 다음 토큰(단어나 기호 등)을 예측합니다.
- 이 과정을 종료 토큰(EOS)이 나올 때까지 반복하면 최종적으로 원하는 시퀀스(예: 번역문)를 완성합니다.
✔︎ Self-Attention
셀프 어텐션은 입력 시퀀스 내의 각각의 요소(토큰, 단어)가 스스로 다른 모든 요소와의 관계를 동적으로 계산해, 중요한 정보에 집중할 수 있게 하는 메커니즘입니다.
- 한 문장의 각 단어가 자신과 다른 단어들과의 관련성을 계산합니다
- ex. "나는 학생입니다" 문장에서 '나'라는 단어가 '학생'과 얼마나 관련 있는지 스스로 계산
✔︎ Cross-Attention
크로스 어텐션은 두 개의 서로 다른 입력 시퀀스 간의 관계를 계산하여, 한 시퀀스가 다른 시퀀스의 중요한 정보에 집중할 수 있게 하는 메커니즘입니다.
- 번역 모델에서 생성중인 문장(타겟)이 원문(소스) 내의 중요한 정보에 집중할 때 사용
- ex. 영어 문장을 한국어로 번역할 때, 생성 중인 한국어 단어가 원본 영어 문장의 단어들과 연결되어 가장 관련있는 단어에 집중
| 입력 타입 | 하나의 시퀀스 내에서 | 두 개의 서로 다른 시퀀스 |
| 쿼리/키/밸류 | 모두 동일한 시퀀스에서 생성 | 쿼리: 타겟(디코더), 키/밸류: 소스(인코더) |
| 주 사용 위치 | 인코더/디코더 내부 | 디코더 |
| 용도 | 내부 시퀀스 내 관계 파악 | 소스와 타겟 간 관련성 파악 |
| 예시 | 문장 내 단어들 간 문맥 파악 | 번역 등에서 원문과 번역문의 연관성 처리 |
'딥러닝' 카테고리의 다른 글
| Paper (0) | 2026.01.03 |
|---|---|
| RNN(Recurrent Neural Networks) (8) | 2025.07.22 |

댓글